SQL server Indexes are implemented as type of BALANCED TREE,
or B-tree (absolute difference between heights of left sub-tree and right
sub-tree is not greater than 1) structure similar more concepts tree, the B-tree
diagram consists of roots non-leaf level and leaf-level, however in the B-tree
diagram, the tree analogy is inverted, indexes have a single root page.

SQL server always uses this (root page) as starting point
for traversing an index. In an Index tree all the index levels above the leaf-levels
include in the root known as non-leaf levels. The leaf-level is the bottom
level of index structure. It contains the key value index entries either
reference rows in the data pages or complete data rows.
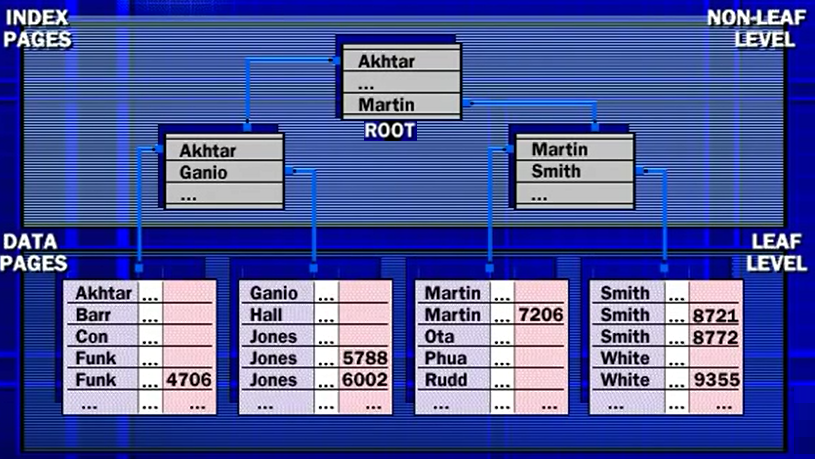
SQL server supports two types of indexes, clustered and
non-clustered, both types of the indexes have similar B-tree structures. In a
clustered index the leaf-level is the actual data page, for a table with
clustered index the data is physically stored on a data page in ascending
order, the order of the value is in the index page is also ascending.
SQL server internally maintains uniqueness of key values for
a clustered index, even if the column data is not unique. It does this
automatically by generating the value that stored with the duplicate key value.
For example, in the first instance of “Jones” is added, all key values are
still unique, when subsequent values of “Jones” are added, SQL server generates
an internal number that system uses to maintains uniqueness among these duplicate
keys, this enables SQL server to differentiate between all instances of “Jones”.

Table: member
Column
Name
|
Data
Type
|
member_no
|
Int
|
Lastname
|
Varchar(50)
|
Firstname
|
Varchar(50)
|
Salary
|
Decimal(10,2)
|
Let us take a close look at how the SQL server navigates a clustered
index, in this example a clustered index is build on lastname column, the query, searching for rows where lastname equal
to “Rudd”.
CREATE TABLE [dbo].[member](
[member_no] [int] IDENTITY(1,1) NOT NULL,
[lastname] [varchar](50) NULL,
[firstname] [varchar](50) NULL,
[salary] [decimal](10,2)
NULL
)
GO
CREATE CLUSTERED INDEX [IX_member_lastname] ON
[member]
(
[lastname] ASC
)
WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY]
GO
SELECT lastname, firstname FROM
member WHERE lastname =
'Rudd'

SQL Server starts at the root page, the value with “Rudd”
>= the key value “Akthar”, the comparison of value is true, and sql server
moves the next key value, SQL server value with “Rudd” is >= the key value
“Martin” the comparison of value which is true and this(Martin) is the last key
value on the page.

SQL server moves to the page at next level where the key
value “Martin” points, SQL server a value with “Rudd” is >= the key value
“Martin”, the comparison of value which is true and SQL server moves the next
key value, SQL server a value with “Rudd” is >= the key value “Smith”, the
comparison of value which is false.

SQL server uses the previous key value “Martin” and moves to
the page at next level where the key value “Martin” points, SQL server reads
through the data page until it finds “Rudd” and then returns to the query
processors.

Now let us take a look at non-clustered indexes, non-clustered
indexes have the same B-tree structure as clustered indexes with one
significant difference, the leaf-level of a non-clustered index contains key
values not the actual data. These key values map to pointers or clustering keys
the locate rows in the data pages,

the implementation of a non-clustered index depends on
whether the data pages of a table are managed as a heap or as a clustered
index, in a non-clustered index built on a heap SQL server uses pointers in a
leaf-level index pages the pointer row in the data pages, if you have a table with
clustered index, SQL server builds the non-clustered indexes on top of the
clustered index structure, in a non-clustered index built on a clustered index,
SQL server uses clustering keys in the leaf-level pages of the non-clustered indexes
to point to the clustered index

Now let us take a closer look at how SQL server navigates on
non-clustered index on a heap, in this example the non-clustered index has been
created on the lastname column. The
query is searching for rows where lastname =”Rudd” from member table
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[member]') AND type in (N'U'))
DROP TABLE
[dbo].[member]
GO
CREATE TABLE [dbo].[member](
[member_no] [int] IDENTITY(1,1) NOT NULL,
[lastname] [varchar](50) NULL,
[firstname] [varchar](50) NULL,
[salary]
[decimal](10,2) NULL
)
GO
CREATE NONCLUSTERED INDEX [IX_member_lastname] ON
[member]
(
[lastname] ASC
)
WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY]
GO
SELECT lastname, firstname FROM
member WHERE lastname =
'Rudd'

SQL server starts at the root level of the non-clustered
index, the value with “Rudd” >= the key value “Akthar”, the comparison of
value is true, and SQL server moves the next key value, SQL server value with
“Rudd” is >= the key value “Martin” the comparison of value which is true
and Martin is the last key value on the page and the value with true as the
result, SQL server moves to the page at next level where the key value “Martin”
points,

SQL server a value with whether “Rudd” is >= the key
value “Martin”, the comparison of value which is true and SQL server moves the
next key value, SQL server a value with whether “Rudd” is >= the key value
“Smith”, the comparison of value which is false.

SQL server uses the
previous key value “Martin” and moves to the page at next level where the key
value “Martin” points, SQL server reads through the leaf page to find “Rudd”
and it uses the pointers to locate the data page and fetch the key value is =
“Rudd”, SQL server returns to this row to the query processors.

Now let us take a look at how SQL server navigates a non-clustered
index using the clustering key, in this example, a non-clustered index has been
created on member_no column, the
table has a clustered index to find on the lastname
column, the query is searching for rows the member_no is = 6078,
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[member]') AND type in (N'U'))
DROP TABLE
[dbo].[member]
GO
CREATE TABLE [dbo].[member](
[member_no] [int] IDENTITY(1,1) NOT NULL,
[lastname] [varchar](50) NOT NULL,
[firstname] [varchar](50) NULL,
[salary]
[decimal](10,2) NULL
)
GO
CREATE CLUSTERED INDEX [IX_member_lastname] ON
[member]
(
[lastname] ASC
)
WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY]
GO
/*
ALTER TABLE
[member] ADD CONSTRAINT [PK_member_lastname] PRIMARY KEY --- > CLUSTERED
(
[lastname] ASC
)WITH
(PAD_INDEX = OFF, IGNORE_DUP_KEY =
OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
GO
*/
CREATE NONCLUSTERED INDEX [IX_member_member_no] ON
[member]
(
[member_no] ASC
)
WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY]
GO
SELECT lastname, firstname FROM
member WHERE member_no =
6078
SQL server starts at root level of the non-clusterd index
the value with whether 6078 is >= 1234, the comparison is true, then SQL
server moves to the next key value, SQL server the value with whether 6078 is
>= the key value 5678, the comparison is true, 5678 is the last key value on
the page and value with true as the result.
SQL server moves to the next levelwhere the key value 5678
points, SQL server evaluates whether 6078 is >= the key value 5678, the
comparison is true, and SQL server moves to the next key value, SQL server
evaluates the key value whether 6078 is >= 7678, the comparison is false,
SQL server uses the previous key value 5678, and moves to the page at the next
level where the key value 5678 points, SQL server reads through the leaf-level pages
until it finds the key value 6078, this key value maps to the clustering key
value “Rudd”, SQL server uses this value (“Rudd”) to navigate through the
clustered index from the root level to retrieve the row in which “Rudd” is the
lastname,

In summary the leaf-level of a clustered index is the actual
data page, data is physically stored on a data page in ascending order, the
leaf-level of a non-clustered index contains key values not the actual data,
these key values map to pointers or clustering key that locates rows in data
pages.

CLUSTERD INDEX vs NONCLUSTERD INDEX
What are the differences between CLUSTERD INDEX and NONCLUSTERD INDEX [CLUSTERD INDEX vs NONCLUSTERD INDEX
CLUSTERED INDEX
|
NONCLUSTERED INDEX
|
|
1
|
The leaf-level of a CLUSTERED INDEX is the actual data page; data is
physically stored on a data page in ascending order.
|
The leaf-level of a NONCLUSTERED INDEX contains key values not
the actual data, these key values map to pointers or clustering key that
locates rows in data pages.
|
2
|
Table can have only one CLUSTERED INDEX.
|
Table can have more
than one NONCLUSTERED INDEX.
SQL server 2008 and
later versions, Maximum 999 Non Clustered Indexes can be created on a
table.
|
3
|
When you create a
PRIMARY KEY on a table, SQL server creates a CLUSTERED INDEX automatically on the table unless specified
“CLUSTERED or NON CLUSTERED”
NOTE: Create the
PRIMARY Key column with CLUSTERED INDEX by
specifying “CLUSTERED”)
EXAMPLE:
CREATE TABLE [dbo].[member](
[member_no]
[int] IDENTITY(1,1) NOT NULL,
[lastname]
[varchar](50)
NOT NULL,
[firstname]
[varchar](50)
NULL,
[salary]
[decimal](10,2) NULL
)
GO
ALTER TABLE [member] ADD CONSTRAINT
[PK_member_lastname] PRIMARY KEY --NONCLUSTERED
(
[lastname]
ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF,ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY]
GO
|
When you create a
PRIMARY KEY on table, SQL server creates a NONCLUSTERED INDEX automatically by specifying “NONCLUSTERED”,
it is not recommended.
EXAMPLE:
CREATE TABLE [dbo].[member](
[member_no]
[int] IDENTITY(1,1) NOT NULL,
[lastname]
[varchar](50)
NOT NULL,
[firstname]
[varchar](50)
NULL,
[salary]
[decimal](10,2) NULL
)
GO
ALTER TABLE [member] ADD CONSTRAINT
[PK_member_lastname] PRIMARY KEY NONCLUSTERED
(
[lastname]
ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF,ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS
= ON, FILLFACTOR = 90) ON [PRIMARY]
GO
|
4
|
Data retrieval is faster than NONCLUSTERED INDEX,because
the leaf level is the bottom level of CLUSTERED INDEX contains the data pages
or complete data rows.
|
Data retrieval is slower than CLUSTERED INDEX, because the
leaf-level is the bottom level of a NONCLUSTERED INDEX contains key values not the actual data.
These key values map to pointers or clustering keys the locate rows in the
data pages.
|
5
|
Do not need extra
space to store logical structure.
CLUSTERED INDEX stores
the base table data in same physical order as index’s logical order, so it
does not require additional storage space.
|
Use extra space to
store logical structure.
In a NONCLUSTERED
INDEX, the index is stored in a separate location which requires additional
storage space.
|
What are the differences between Table Scan, Index Scan and Index Seek?
TABLE SCAN:
The SQL Server optimizer's job is to choose the best way to
execute a query. The optimizer uses indexes to improve query execution time.
When you query a table that doesn't have indexes, or if the optimizer decides
not to use an existing index or indexes, the system performs a table scan.
In a table scan, SQL Server sequentially (row by row) reads the
table's data pages to find rows that belong to the result set.
EXAMPLE:
-- Create a Table with out Index
CREATE TABLE [dbo].[ScanSeek](
[ScanSeekID]
[int] IDENTITY(1,1) NOT NULL,
[ScanSeekValue]
[varchar](100) NULL
)
GO
-- Insert 1 Lac Records to ScanSeek
table.
VALUES (CONVERT (VARCHAR(100), (SELECT ISNULL(MAX(ScanSeekID),0) + 1 FROM
[ScanSeek] WITH (NOLOCK))))
GO 100000
-- Select all the records from ScanSeek
table.
SELECT [ScanSeekID],
[ScanSeekValue]
FROM [dbo].[ScanSeek] WITH (NOLOCK)
GO
-- Select a record from ScanSeek table
where ScanSeekID = 100.
SELECT [ScanSeekID],
[ScanSeekValue]
FROM [dbo].[ScanSeek] WITH (NOLOCK)
WHERE [ScanSeekID] = 100
GO

From the above two
select queries, either to fetch all the records from table OR to fetch only one
the matched record from table where ScanID=100, while seeing the execution plan
the Cost is 100%, so it is obviouly bottleneck for the performance,
From the second
SELECT query, the query optimizer used the table scan which means it
reads/scans 100000 (1Lac) records sequentially row by row of the table for
fetching the matched row.
How to overcome this issue OR to fetch only the matched
records from table?
Adding/creating
appropriate indices on table that helps for retriving the data fast.
INDEX SCAN:
An index scan is,
scan the data or index pages to find the appropriate records, an index scan
retrieves all the rows from the table, it means that all the leaf-level of the
index was searched to find the information for the query,
There are two types
of Index Scan.
- Index Scan on Clustered Index
- Index Scan On Non-Clustred Index
1.
Index
Scan on Clustered Index - In a table, when the index is a clustered
index and search key column is not indexed, in this case, SQL server navigates
from root level to leaf-level (data pages)
until the data match, which means that scanning the data page by using the clustring
key value as a pointer/reference.
-- Create a Table without Index
CREATE TABLE [dbo].[ScanSeek](
[ScanSeekID] [int] IDENTITY(1,1) NOT NULL,
[ScanSeekValue] [varchar](100) NULL
)
GO
-- Insert 1 Lac Records to ScanSeek table.
INSERT INTO ScanSeek (ScanSeekValue)
VALUES (CONVERT (VARCHAR(100), (SELECT ISNULL(MAX(ScanSeekID),0) + 1
FROM
[ScanSeek] WITH (NOLOCK))))
GO 100000
-- Create a Clustered index on ScanSeek table.
CREATE CLUSTERED INDEX
[PK_ScanSeek_ScanSeekID] ON ScanSeek(ScanSeekID)
WITH (PAD_INDEX
= OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Select all the records from ScanSeek table.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM
[dbo].[ScanSeek] WITH (NOLOCK)
GO
-- Select a record from ScanSeek table where ScanSeekValue = 100.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM
[dbo].[ScanSeek] WITH (NOLOCK)
WHERE
ScanSeekValue = '100'
GO

From the above two select queries, either to fetch all the
records from table OR to fetch only one the matched record from table where
ScanID=100, while seeing the execution plan the Cost is 100%, search column
[ScanSeekValue ] is not Indexed on table,
From the both SELECT queries, the query optimizer used the
clustered Index scan which means retrieving the data by just using the index
tree from root level to leaf-level (data pages) .
2.
Index
Scan On Non-Clustred Index – a table has a cluster and a non-clustered index and search key column
is not specifed, retrieving the data by just using the index tree from root
level to leaf-level pages (key values not the actual data), which means that scanning the leaf-level pages by using the
non-clustring key value as a pointer to the data pages/complete rows.
A non-cluster index built on top of the cluster index
structure. SQL server uses the clustring keys in the leaf-level pages of the
non-cluster index to point to the cluster index.
-- Create a Table without Index
CREATE TABLE [dbo].[ScanSeek](
[ScanSeekID] [int] IDENTITY(1,1) NOT NULL,
[ScanSeekValue] [varchar](100) NULL
)
GO
-- Insert 1 Lac Records to ScanSeek table.
INSERT INTO ScanSeek (ScanSeekValue)
VALUES (CONVERT (VARCHAR(100), (SELECT ISNULL(MAX(ScanSeekID),0) + 1 FROM [ScanSeek] WITH (NOLOCK))))
GO 100000
-- Create a Clustered index on ScanSeek table.
CREATE CLUSTERED INDEX
[PK_ScanSeek_ScanSeekID] ON ScanSeek(ScanSeekID)
WITH (PAD_INDEX
= OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Create a Non Clustered index on ScanSeek table.
CREATE NONCLUSTERED INDEX
[IX_ScanSeek_ScanSeekValue] ON ScanSeek(ScanSeekValue)
WITH (PAD_INDEX
= OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Select all the records from ScanSeek table.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM
[dbo].[ScanSeek] WITH (NOLOCK)
GO

The Clustered Index
Scan operator scans the clustered index specified in the Argument column of the
query execution plan. When an optional WHERE:() predicate is present, only
those rows that satisfy the predicate are returned. If the Argument column
contains the ORDER clause, the query processor has requested that the output of
the rows be returned in the order in which the clustered index has sorted it.
If the ORDER clause is not present, the storage engine scans the index in the
optimal way, without necessarily sorting the output.
INDEX SEEK:
Seek uses the index
to pinpoint the records that are needed to satisfy the query.
There are two types
of Index Seek.
1.
Index
Seek on Clustered Index - a table has clustered index, retrieving the
data by using cluster index column, In Index tree, SQL server navigates from
root level to leaf-level (data pages)
until the data match, which means that pointing the data pages by using the clustring
key value as a pointer/reference.
-- Create a Table without Index
CREATE TABLE
[dbo].[ScanSeek](
[ScanSeekID] [int] IDENTITY(1,1) NOT NULL,
[ScanSeekValue]
[varchar](100) NULL
)
GO
-- Insert 1 Lac Records to ScanSeek table.
INSERT INTO
ScanSeek (ScanSeekValue)
VALUES (CONVERT (VARCHAR(100), (SELECT ISNULL(MAX(ScanSeekID),0) + 1 FROM [ScanSeek] WITH (NOLOCK))))
GO 100000
-- Create a Clustered index on ScanSeek table.
CREATE CLUSTERED
INDEX [PK_ScanSeek_ScanSeekID] ON ScanSeek(ScanSeekID)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Select a record from ScanSeek where ScanSeekID
= 100.
SELECT [ScanSeekID], [ScanSeekValue]
FROM [dbo].[ScanSeek]
WITH (NOLOCK)
WHERE [ScanSeekID] = 100
GO

2.
Index
Seek on Non-Clustered Index -
a table has clustered index and non cluster index, retrieving the data
by using non-cluster index column, In Index tree, SQL server navigates from
root level to data pages until the data match, which means, a non-cluster index
built on top of the cluster index structure. SQL server uses the clustring keys
in the leaf-level pages (key values not the actual data) of the non-cluster index to point to the data
pages.
-- Create a Table without Index
CREATE TABLE [dbo].[ScanSeek](
[ScanSeekID] [int] IDENTITY(1,1) NOT NULL,
[ScanSeekValue] [varchar](100) NULL
)
GO
-- Insert 1 Lac Records to ScanSeek table.
INSERT INTO ScanSeek (ScanSeekValue)
VALUES (CONVERT (VARCHAR(100), (SELECT ISNULL(MAX(ScanSeekID),0) + 1 FROM [ScanSeek] WITH (NOLOCK))))
GO 100000
-- Create a Clustered index on ScanSeek table.
CREATE CLUSTERED INDEX
[PK_ScanSeek_ScanSeekID] ON ScanSeek(ScanSeekID)
WITH (PAD_INDEX
= OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Create a Non Clustered index on ScanSeek table.
CREATE NONCLUSTERED INDEX
[IX_ScanSeek_ScanSeekValue] ON ScanSeek(ScanSeekValue)
WITH (PAD_INDEX
= OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Select a record from ScanSeek where ScanSeekID = 100.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM
[dbo].[ScanSeek] WITH (NOLOCK)
WHERE
[ScanSeekID] = 100
GO
-- Select a record from ScanSeek table where ScanSeekValue = 100.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM
[dbo].[ScanSeek] WITH (NOLOCK)
WHERE
ScanSeekValue = '100'
GO

LOOKUP HEAP:
A table has only non
cluster index, this case SQL server manages the table as Heap, retrieving the data by using non-cluster index
column, In Index tree, SQL server navigates from root level to data pages until
the data match, which means, SQL server uses the leaf-level pages (key values
not the actual data) of the non-cluster
index to point to the Heap.
-- Create a Table without Index
CREATE TABLE [dbo].[ScanSeek](
[ScanSeekID] [int] IDENTITY(1,1) NOT NULL,
[ScanSeekValue] [varchar](100) NULL
)
GO
-- Insert 1 Lac Records to ScanSeek table.
INSERT INTO ScanSeek (ScanSeekValue)
VALUES (CONVERT (VARCHAR(100), (SELECT ISNULL(MAX(ScanSeekID),0) + 1 FROM [ScanSeek] WITH (NOLOCK))))
GO 100000
-- Create a Non Clustered index on ScanSeek table.
CREATE NONCLUSTERED INDEX
[IX_ScanSeek_ScanSeekValue] ON ScanSeek(ScanSeekValue)
WITH (PAD_INDEX
= OFF, STATISTICS_NORECOMPUTE
= OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-- Select a record from ScanSeek where ScanSeekID = 100.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM
[dbo].[ScanSeek] WITH (NOLOCK)
WHERE
[ScanSeekID] = 100
GO
-- Select a record from ScanSeek table where ScanSeekValue = 100.
SELECT
[ScanSeekID], [ScanSeekValue]
FROM [dbo].[ScanSeek] WITH (NOLOCK)
WHERE
ScanSeekValue = '100'

No comments:
Post a Comment