ER Model defines conceptual view of a database. It is a logical relationship of entities (or objects) in order to create a database.
The elements of ER Model are;
· Entity – Entity can be real-world object. It is a collection of related attributes or properties.
Example: Employee, Department, etc.
o Strong
Entity –An entity that
has a primary key is called as Strong entity. Rectangle represents strong
entity.

Example: Employee,
Department, etc, we can use “INNER JOIN” to join between tables.
o Weak
Entity –Weak entity doesn’t
have key attribute (primary key) of its own. Double rectangle represents weak entity.

Example: Employee, Dependant,
Employee can exist without dependants but no dependent can exist without the
employees. We must use “LEFT OUTER JOIN”/ “RIGHT OUTER JOIN” to join between entities.
Differences between Strong Entity and Weak Entity:
#
|
Strong Entity
|
Weak Entity
|
1
|
It has its own primary
key.
|
It does not have
sufficient attributes to form a primary key on its own.
|
2
|
It is represented by a
rectangle.
|
It is represented by a
double rectangle.
|
3
|
It contains a primary
key represented by an eclipse with underline.
|
It contains partial
key or discriminator represented by an eclipse with dashed underline.
|
4
|
The member of strong
entity set is called as dominant entity set
|
The member of weak
entity set is called as subordinate entity set.
|
5
|
The primary key is one
of its attributes which uniquely identifies its member.
|
The primary key of
weak entity set is combination of partial key and primary key of the strong
entity set.
|
6
|
The relationship
between two strong entity set is represented by a diamond symbol.
|
The relationship
between one strong and weak entity set is represented by a double diamond symbol.
|
7
|
The line connecting
strong entity set with identifying the relationship is single.
|
The line connecting
weak entity set with identifying the relationship is double.
|
8
|
Total participation in
the relationship may or may not exists
|
Total participation in
the identifying relationship always exists.
|
· Entity Set – It is a collection of similar type of entities. An entity set may contain entities with attribute sharing similar values.
Example: “Staff” set may contain all the staffs of a company from all employees.
· Attribute - It is a property/element of an object. Entities are named/represented by the means of their properties.
Example: EmployeeName, EmployeeAge, EmployeeSalary, etc,
The various types of Attributes are;





o Simple attribute -
Simple attributes are atomic values, which cannot be divided further. Eclipse
represents key attribute.

Example: An
employee's phone number is an atomic value of 10 digits.Eclipse represents
attribute.
o Composite attribute -
Composite attributes are made of more than one simple attribute.

Example: An
employee's complete name may have FirstName and LastName.
o Derived attribute -
Derived attributes that do not exist in the physical database, but their values
are derived from other attributes present in the database. It depicted by dased
eclipse.

Example:
AverageSalary in a department should not be saved directly in the database,
instead it can be derived. Another example is, Age can be derived from
DateOfBirth.
o Single-value attribute -
Single-value attributes contain single value. It depicted by eclipse with
underlining.

Example: EmployeePAN, EmployeeSSN, etc,
o Multi-value attribute -
Multi-value attributes may contain more than one value. It depicted by doubled
eclipse.

Example: An employee can have more than one EmailAddress,
PhoneNumber, etc,
· Keys - Key is just a single attribute (which is just a column) that can uniquely identify a row.
Example: EmployeeID attribute of Employee table.
The various types of Keys are;
o
Super
Key - A set of attributes (one or more) that collectively
identifies an entity in an entity set. It’s any combination of column(s) for
which that combination of values will be unique across all rows in a table.
Example: EmployeeID is always unique in Employee
table. Combination of EmployeeID and EmployeeName there will be no two rows in
the table that share the exact same combination of values, because the
EmployeeID will always be unique and different for each row.
o
Candidate
Key - A minimal super key is called a candidate key. An entity
set may have more than one candidate key. It is minimum number of columns that
can be used to uniquely identify a single row. In other words, the minimum
number of columns, which when combined, will give a unique value for every row
in the table.
Example: EmployeeID is
always unique in Employee table.
o
Primary
Key - Only one super key is used to uniquely identify a single
row of table is called primary key.
Example: EmployeeID is
always unique in Employee table.
o Foreign Key - It is used to define relationship between two tables..
o
Alternate
Key - Any table have more than one candidate key, then after
choosing primary key from those candidate key, rest of candidate keys are known
as an alternate key of that table.
Example: We have a table named Employee which has
two columns EmployeeID and EmployeeEmail, both have not null attributes and
unique value. So both columns are treated as candidate key. Now we make
EmployeeID as a primary key to that table then EmployeeEmail is known as
alternate key.
o
Composite
Key - Create keys with more than one column then that key is
known as composite key. It is used to uniquely identify a single row of table.
Example:
Combination of (EmployeeID, DegreeID) columns uniquely identified as single row
of EmployeeDegree table.
·
Mapping
Cardinalities (Relations) - Cardinality defines
the number of entities in one entity set, which can be associated with the
number of entities of other set called relations.
Relationships are defined on the basis of
matching key columns. In SQL server, these relationships are defined using Primary
Key-Foreign Key constraints. Rhombus/Diamond represents relationship.

There are three types of relationship that exist
between Entities.
o Binary Relationship - Relationship means relation between two
Entities.
o Unary/Recursive Relationship - An Entity is related with itself.
o Ternary Relationship - Relationship
of degree (number) three is called Ternary relationship.
The various types of Relationship are;
- One to One
One element of entity/table can be associated
with at most one element of another entity(table) and vice versa.
Example: An employee must have one address.

- One to Many
One element of entity/table can be associated
with more than one elements of another entity(table).

Example: An employee holds many degrees.
- Many to One
More than one elements of entity/table can be
associated with at most one element of another entity(table).

Example: Many employees belong to one department.
- Many to Many
One element of entity/table can be associated
with more than one elements of another entity(table) and vice versa.
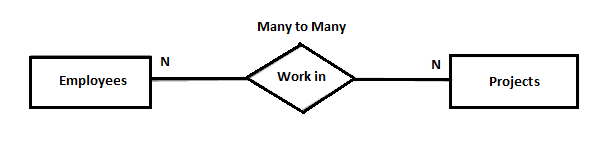
Example: Many employees are associated to one
project and many projects are assigned to many employees.
- Unary/Recursive Relationship
An entity is related with itself

Example: Employee table has columns like EmployeeID and ManagerID. Here EmployeeID is candidate key/ primary key of Employee table, Employee table’s ManagerID column is associated with same Employee table EmployeeID
- Ternary Relationship
Relationship of degree (number) three is called
Ternary relationship.

Example: Employees are associated to Projects and Technologies, Technologies associated to Projects.
Entity Relationship Diagram
Entity Relationship Diagram is a graphical representation of logical relationship among entities (tables) in the database.
ER diagram depicts the attributes
relationship among entities/entity set.
Symbols and Notations for ER
Diagram are as follows.

Example for ER Diagram:

Try it out:
1) Understand the above diagram and write the requirements.
2) Draw
an ERD for following system and create a database design.
- Allows to store number (ID), first name, last
name, gender, date of birth, PAN, salary, reporting manager, street address,
city and zip and qualifications/degrees (SSLC, PUC, BSc, MSc, Phd) of employees.
(number would be used to identify the unique record of employee)
- Allows storing number (ID), name and
technologies (PHP, SQL, HTML) of projects. (number would be used to identify
the unique record of project)
- Allows storing identification number, name, street
address, city and zip of company (number would be used to identify the unique
record of company)
- Employee can exist without project,
- Allows storing percentage of allocation of each
project to the assigned Employee
- Employees must belong to a company
- Qualifications must be stored in a separate
entity named as degree
- Employee holds one or many qualifications
- Allows storing multiple technologies of project
- Allows getting the average salary of employees
- Search allows for getting the employee record
based on first name and last name